| Version 8 (modified by , 16 years ago) ( diff ) |
|---|
Examples Network Topology
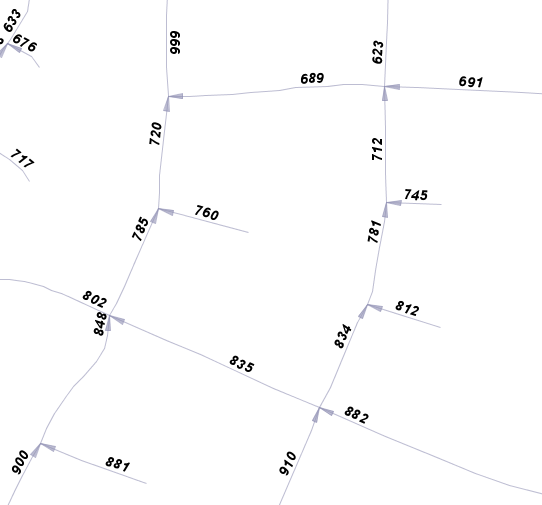
Suppose you had a table of linestrings that represented a linear network (i.e. roads). Here's one approach to linking the line segments together via to_node / from_node attributes.

- First, generate a table of distinct nodes, that is, a distinct collection of all the start and end points of the line segments.
CREATE TABLE nodes AS
SELECT
the_geom,
array_accum(road_leaving) AS road_leaving,
array_accum(road_entering) AS road_entering
FROM (
SELECT
ST_StartPoint(the_geom) AS the_geom,
road_id AS road_leaving,
NULL::integer AS road_entering
FROM roads
UNION ALL
SELECT
ST_EndPoint(the_geom) AS the_geom,
NULL::integer AS road_leaving,
road_id AS road_entering
FROM roads
) AS foo
GROUP BY the_geom;
The above query creates a node table from a roads table by selecting all the start and end points from the road segments while maintaining the link between the node geometry and the line segment id. Then, nodes are grouped into a single topologically distinct set where every POINT references an array of line segment ids as integer[].
-- node table DDL CREATE TABLE nodes ( the_geom geometry, road_leaving integer[], road_entering integer[] );
Note: This step made use of the aggregate function 'array_accum', which for some reason is not defined by default in postgresql, but can be added to any database easy enough.
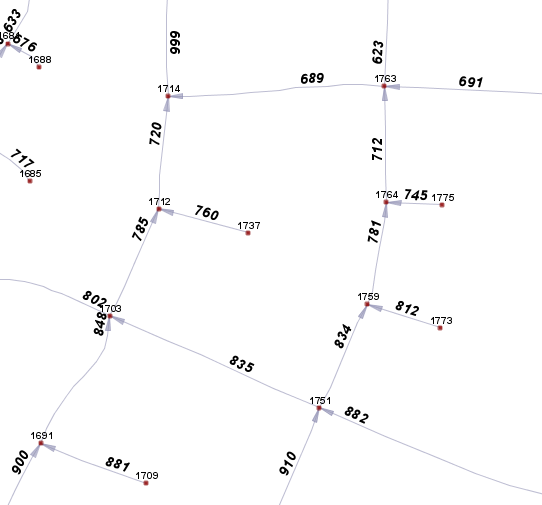
- The next step is to assign a unique id for each node and to add two new attributes to the roads table to hold the node references.
ALTER TABLE nodes ADD COLUMN node_id serial;
ALTER TABLE nodes ADD PRIMARY KEY (node_id);
ALTER TABLE roads ADD from_node integer;
ALTER TABLE roads ADD to_node integer;
-- Sample data in table
SELECT node_id, road_leaving, road_entering FROM nodes WHERE node_id = 1764;
node_id | road_leaving | road_entering
---------+-----------------+----------------
1764 | {712,NULL,NULL} | {NULL,781,745}
(1 row)
- Now that we have our node table with line segment references, we want to update the from_node and to_node attributes of the roads table to reference the appropriate node. The obvious first approach would be to simply update the roads table using the appropriate reference in the nodes table:
UPDATE roads a SET from_node = b.node_id FROM nodes b WHERE a.road_id = ANY (b.road_leaving); UPDATE roads a SET to_node = b.node_id FROM nodes b WHERE a.road_id = ANY (b.road_entering);
Unfortunately, PostgreSQL does not seem to make use any btree indexes we might have placed on the id arrays, road_leaving and road_entering. Such queries estimated to take many hours to execute on a small table of 50000 roads. Subsequently, the following approach can be taken:
CREATE TABLE nodes_expanded AS
SELECT
node_id,
road_leaving[leaving_upper],
road_entering[entering_upper]
FROM (
SELECT
node_id,
road_leaving,
generate_series(1, array_upper(road_leaving, 1)) AS leaving_upper,
road_entering,
generate_series(1, array_upper(road_entering, 1)) AS entering_upper
FROM nodes
) AS foo;
CREATE UNIQUE INDEX nodes_expanded_leav_idx ON nodes_expanded (road_leaving);
CREATE UNIQUE INDEX nodes_expanded_ent_idx ON nodes_expanded (road_entering);
ANALYZE nodes_expanded;
The above query expands the node table, essentially removing the integer array field we created earlier.
Now we can update our roads table with appropriate from_node / to_node values taking mere seconds to process.
UPDATE roads a SET from_node = b.node_id FROM nodes_expanded b WHERE a.road_id = b.road_leaving; UPDATE roads a SET to_node = b.node_id FROM nodes_expanded b WHERE a.road_id = b.road_entering;

-- Sample data from the new roads table
SELECT road_id, from_node, to_node FROM roads WHERE road_id = 834;
road_id | from_node | to_node
---------+-----------+---------
834 | 1751 | 1759
(1 row)
Notes: Alternatively, we could have first created a distinct set of nodes, assigned a unique id to the nodes, and spatially transferred a node_id attribute to every road by intersecting the roads and nodes. However, such spatial operations are very expensive to perform. Also, in this case, it's not needed since we already have a relationship between a line and a node (the node is just the start or end point of the line it originated from).
Attachments (2)
-
network_topology1.png
(25.0 KB
) - added by 16 years ago.
network_topology1.png
-
network_topology2.png
(28.3 KB
) - added by 16 years ago.
network_topology2.png
{kind=link}
{kind=link}
Download all attachments as: .zip