
| Version 17 (modified by , 11 years ago) ( diff ) |
|---|
Table of Contents
Testing framework for GRASS GIS
| Title: | Testing framework for GRASS GIS |
| Student: | Vaclav Petras, North Carolina State University, Open Source Geospatial Research and Education Laboratory |
| Organization: | OSGeo - Open Source Geospatial Foundation |
| Mentors: | Sören Gebbert, Helena Mitasova |
| GSoC link: | abstract |
Abstract
GRASS GIS is one of the core projects in the OSGeo Foundation. GRASS provides wide range of geospatial analyses including raster and vector analyses and image processing. However, there is no system for regular testing of it's algorithms. To ensure software quality and reliability, a standardized way of testing needs to be introduced. This project will implement a testing framework which can be used for writing and running tests of GRASS GIS modules, C/C++ libraries and Python libraries.
Introduction
GRASS GIS is one of the core projects in the OSGeo Foundation and is used by several other free and open source projects to perform geoprocessing tasks. The software quality and reliability is crucial. Thus, proper testing is needed. So far, the testing was done manually by both developers and users. This is questionable in terms of test coverage and frequency of the tests and moreover, it is inconvenient. This project will implement a testing framework which can be used for writing and running tests for GRASS GIS. This will be beneficial not only for the quality of GRASS GIS but also for everyday development of GRASS GIS because it will help to identify problems with the new code at the time when the change is done.
Background
There was already several attempts to establish testing infrastructure for GRASS GIS, namely quality assessment and monitoring mailing list which is inactive for several years, then older test suite which was never integrated into GRASS GIS itself, and most recently a test suite proposal which was trying to interpret shell scripts as test cases. Also, an experience with usage of Python doctest at different circumstances shows that this solution is not applicable everywhere.
These previous experiences give us a clear idea what is not working (e.g. tests outside main source code), what is overcomplicated (e.g. reimplementing shell) and what is oversimplified (e.g. shell scripts without clear set up and tear down steps), and point us to the direction of an implementation which will be most efficient (general but simple enough), integrated in GRASS source code, and which will be accepted by the GRASS development team. The long preceding discussions also showed what is necessary to have in the testing framework and what should be left out.
The idea
The purpose of this project is to develop a general mechanism which would be applicable for testing GRASS modules, libraries or workflows with different data sets. Tests will be part of GRASS main source code, cross-platform, and as easy to write and run as possible. The testing framework will enable the use of different testing data sets because different test cases might need special data. The testing framework will be implemented in Python and based on testing tools included in standard Python distribution (most notably unittest) which will not bring a new dependency but also it will avoid writing everything from scratch. The usage of Makefile system will be limited to triggering the test or tests with the right parameters for particular location in the source tree, everything else will be implemented in Python to ensure maximum re-usability, maintainability, and availability across platforms.
This project will focus on building infrastructure to test modules, C/C++ libraries (using ctypes interface), and Python libraries. It is expected that testing of Python GUI code will be limited to pure Python parts. The focus will be on the majority of GRASS modules and functionality while special cases such as rendering, creation of locations, external data sources and databases, and downloading of extensions from GRASS Addons will be left for future work. Moreover, this project will not cover tests of graphical user interface, server side automatic testing (e.g. commit hooks), using testing shell scripts or C/C++ programs, and testing of internal functions in C/C++ code (e.g. static functions in libraries and functions in modules). Creation of HTML, XML, or other rich outputs will not be completely solved but the implementation will consider the need for a presentation of test results. Finally, writing the tests for particular parts will not be part of this project, however several sample tests for different parts of code, especially modules, will be written to test the testing framework.
Project plan
| date | proposed task |
| 2014-05-19 - 2014-05-23 (week 01) | Designing a basic template for the test case and interface of test suite class(es) |
| 2014-05-26 - 2014-05-30 (week 02) | Basic implementation |
| 2014-06-02 - 2014-06-06 (week 03) | Dealing with evaluation and comparison of textual and numerical outputs |
| 2014-06-09 - 2014-06-13 (week 04) | Dealing with evaluation and comparison of map outputs and other outputs |
| 2014-06-16 - 2014-06-20 (week 05) | Re-writing some existing tests using testing framework |
| 2014-06-23 - 2014-06-27 (week 06) | Testing of what was written so far and evaluating current design and implementation |
| June 23 | Mentors and students can begin submitting mid-term evaluations |
| June 27 | Mid-term evaluations deadline |
| 2014-06-30 - 2014-07-04 (week 07) | Integration with GRASS source code, documentation and build system |
| 2014-07-07 - 2014-07-11 (week 08) | Implementation of location switching |
| 2014-07-14 - 2014-07-18 (week 09) | Dealing with evaluation and comparison of so far unresolved outputs |
| 2014-07-21 - 2014-07-25 (week 10) | Implementing the basic test results reports |
| 2014-07-28 - 2014-08-01 (week 11) | Re-writing some other existing tests using testing framework |
| 2014-08-04 - 2014-08-08 (week 12) | Writing documentation of framework internals and guidelines how to write tests |
| 2014-08-11 - 2014-08-15 (week 13) | Polish the code and documentation |
| August 11 | Suggested 'pencils down' date. Take a week to scrub code, write tests, improve documentation, etc. |
| 2014-08-18 - 2014-08-22 (week 14) | Submit evaluation and code to Google |
| August 18 | Firm 'pencils down' date. Mentors, students and organization administrators can begin submitting final evaluations to Google. |
| August 22 | Final evaluation deadline |
| August 22 | Students can begin submitting required code samples to Google |
Design of testing API and implementation
import unittest
import grass.pygrass.modules as gmodules
# alternatively, these can be private to module with setter and getter
# or it can be in a class
USE_VALGRIND = False
class GrassTestCase(unittest.TestCase):
"""Base class for GRASS test cases."""
def run_module(self, module):
"""Method to run the module. It will probably use some class or instance variables"""
# get command from pygrass module
command = module.make_cmd()
# run command using valgrind if desired and module is not python script
# see also valgrind notes at be end of this section
if is_not_python_script(command[0]) and USE_VALGRIND:
command = ['valgrind', '--tool=...', '--xml=...', '--xml-file=...'] + command
# run command
# store valgrind output (memcheck has XML output to a file)
# store module return code, stdout and stderr, how to distinguish from valgrind?
# return code, stdout and stderr could be returned in tuple
def assertRasterMap(self, actual, reference, msg=None):
# e.g. g.compare.md5 from addons
# uses msg if provided, generates its own if not,
# or both if self.longMessage is True (unittest.TestCase.longMessage)
# precision should be considered too (for FCELL and DCELL but perhaps also for CELL)
# the actual implementation will be in separate module, so it can be reused by doctests or elsewhere
# this is necessary considering the number and potential complexity of functions
# and it is better design anyway
if check sums not equal:
self.fail(...) # unittest.TestCase.fail
class SomeModuleTestCase(GrassTestCase):
"""Example of test case for a module."""
def test_flag_g(self):
"""Test to validate the output of r.info using flag "g"
"""
# Configure a r.info test
module = gmodules.Module("r.info", map="test", flags="g", run_=False)
self.run_module(module=module)
# it is not clear where to store stdout and stderr
self.assertStdout(actual=module.stdout, reference="r_info_g.ref")
def test_something_complicated(self):
"""Test something which has several outputs
"""
# Configure a r.info test
module = gmodules.Module("r.complex", rast="test", vect="test", flags="p", run_=False)
(ret, stdout, stderr) = self.run_module(module=module)
self.assertEqual(ret, 0, "Module should have suceed but return code is not 0")
self.assertStdout(actual=stdout, reference="r_complex_stdout.ref")
self.assertRasterMap(actual=module.rast, reference="r_complex_rast.ref")
self.assertVectorMap(actual=module.vect, reference="r_complex_vect.ref")
Compared to suggestion in ticket:2105#comment:4 it does not solve everything in test_module (run_module) function but it uses self.assert* similarly to unittest.TestCase which (syntactically) allows to check more then one thing.
Test script should be importable
Test scripts must have module/package character (as unittests requires for test discovery). This applies true for unittests and doctests, no exceptions. Doctests (inside normal module code or in separate doc) will be wrapped as unittest test cases (in testsuite directory). There is a standard way to do it. To have the possibility of import, all the GRASS Python libraries shouldn't do anything fancy at import time. For example, doctests currently don't work with grass.script unless you call a set of functions to deal with function _ because of installing translate function as buildin _ function while _ is used also in doctest. (This is fixed for GUI but still applies to Python libraries).
Dealing with process termination
There is no easy way how to test that (GRASS) fatal errors are invoked when appropriate. Even if the test method (test_*) itself would run in separate process (not only the whole script) the process will be ended without proper reporting of the test result (considering we want detailed test results). However, since this applies also to fatal errors invoked by unintentional failure and to fatal errors, it seems that it will be necessary to invoke the test methods (test_*) in a separate process to at least finish the other tests and not break the final report. This might be done by function decorator so that we don't invoke new process for each function but only for those who need it (the ones using things which use ctypes).
Analyzing module run using Valgrind or others
Modules (or perhaps any tests) can run with valgrind (probably --tool=memcheck). This could be done on the level of testing classes but the better option is to integrate this functionality (optional running with valgrind) into PyGRASS, so it could be easily usable through it. Environmental variable (GRASS_PYGRASS_VALGRIND) or additional option valgrind_=True (similarly to overwrite) would invoke module with valgrind (works for both binaries and scripts). Additional options can be passed to valgrind using valgrind's environmental variable $VALGRIND_OPTS. Output would be saved in file to not interfere with module output.
We may want to use also some (runtime checking) tools other than valgrind, for example clang/LLVM sanitizers (as for example Python does). However, it is unclear how to handle more than one tool as well as it is unclear how to store the results for any of these (including valgrind) because one test can have multiple module calls (or none), module calls can be indirect (function in Python lib which calls a module or module calling module) and there is no standard way in unittest to pass additional test details.
PyGRASS or specialized PyGRASS module runner (function) in testing framework can have function, global variable, or environmental variable which would specify which tool should run a module (if any) and what are the parameters (besides the possibility to set parameters by environmental variable defined by the tool). The should ideally be separated from the module output and go to a file in the test output directory (and it could be later linked from/included into the main report).
Having output from many modules can be confusing (e.g. we run r.info before actually running our module). It would be ideal if it would be possible to specify which modules called in the test should run with valgrind or other tool. API for this may, however, interfere with the API for global settings of running with these tools.
It is not clear if valgrind would be applied even for library tests. This would require to run the testing process with valgrind. But since it needs to run separately anyway, this can be done. In case we would like to run with valgrind test function (test_*), the testing framework would have to contain the valgrind running function anyway. The function would run the test function as subprocess (which is anyway necessary to deal with process termination). The advantage of integration into PyGRASS wouldn't be so big in this case. But even in the case of separate function for running subprocess, a PyGRASS Module class will be used to pass the parameters.
Dependencies
Dependencies on other tests
The test runner needs to know if the dependencies are fulfilled, hence if the required modules and library tests were successful. So there must be a databases that keeps track of the test process. For example, if the raster library test fails, then all raster test will fail, such a case should be handled. The tests would need to specify the dependencies (there might be even more test dependencies then dependencies of the tested code).
Alternatively, we can ignore dependency issues. We can just let all the tests fail if dependency failed (without us checking that dependency) and this would be it. By tracking dependencies you just save time and you make the result more clear. Fail of one test in the library, or one test of a module does not mean that the test using it was using the broken feature, so it can be still successful (e.g. failed test vector library 3D capabilities and module accessing just 2D geometries). Also not all tests of dependent code have to use that dependency (e.g. particular interpolation method).
The simplest way to implement parallel dependency checking would be to have a file lock (e.g., Cross-platform API for flock-style file locking), so that only a single test runner has read and write access to the test status text file. Tests can run in parallel and have to wait until the file is unlocked. Consequently the test runner should not crash so that the file lock is always removed.
Anyway, dependency checking may be challenging if we allow parallel testing. Not allowing parallel testing makes the test status database really simple, it's a text file that will be parsed by the test runner for each test script execution and extended with a new entry at the end of the test run. Maybe at least the library test shouldn't be executed in parallel (something might be in the make system already).
Logs about the test state can be used to generate a simple test success/fail overview.
Dependencies of tested code
Modules such as G7:r.in.lidar (depends on libLAS) or G7:v.buffer (depends on GEOS) are not build if the dependencies are not fulfilled. It might be good to have some special indication that the dependency is missing but this might be also leaved as task of test author who can implement special test function which will just check the presence of the module. Thus that the tests failed because of missing dependency would be visible in the test report.
Reports from testing
Everything should go (primarily) to files and directories with some defined structure. Something would have to gather information from files and build some main pages and summary pages. The advantage of having everything in files is that it might be more robust and that it can easily run in parallel. However, gathering of information afterwards can be challenging. Files are really the only option how to integrate valgrind outputs.
There is TextTestRunner in unittest, the implementation will start from there. For now, the testing framework will focus on HTML output. However, the goal is something like GRASSTestRunner which could do multiple outputs simultaneously (in the future) namely HTML, XML (there might be some reusable XML schemes for testing results) and TXT (might be enriched by some reStructuredText or Markdown or really plain). Some (simple) text (summary) should go in to standard output in parallel to output to files.
It is not clear if the results should be organized by test functions (test_*) or only by test scripts (modules, test cases).
The structure of report will be based on the source code structure (something can be separate pages, something just page content):
libgisgmath- ... (other libraries)
rasterr.slope.aspect- ... (other modules)
vectorv.edit(testsuitedirectory is at this level)- test script/module
TestCaseclasstest_function/method- standard output
- error output
- ... (other details)
- test script/module
There will be (at least one) top level summary page with percentages and links to subsections.
It is not clear how to deal with libraries with subdirectories (such as lib/vector/vedit/) and groups of modules (such as raster/simwe/). Will each module have separate tests? Will the common library be tested (by programs/modules in case of C/C++, by standard tests in case of Python)? The rule of thumb would be to put all directories with testsuite directory on the same level. This is robust for any level of nesting and for directories having testsuite directory together with subdirectories having their own testsuite directories. In this system, a testsuite directory would be the only element and its attribute is the original directory in the code where it was discovered. Any higher level pages in report would have reconstruct the structure from these attributes. The advantage is that we can introduce different reconstructions with different simplifications, for example we can have lib (except for lib/python), lib/python, vector, etc. or we can have just everything on the same level, or just a selection (raster modules or everything useful for vectors from lib, lib/python and both raster and vector modules).
We can introduce a rule that each test script/module can contain only one TestCase class which would simplify the tree. However, this is probably not needed because both the implementation and the representation can deal with this easily.
A page for testsuite will be the "central" page of the report. There will be list (table) of all test scripts/modules, their TestCase classes, and their test_ functions/methods with basic info and links to details. Considering amount of details there will be probably a separate page for each test_ function/method.
Details for one test (not all have to be implemented):
- standard output and standard error output of tests
- it might be hard to split if more than one module is called (same applies to functions)
- might be good to connect them since they are sometimes synchronized (e.g., in case of G7:g.list)
- Valgrind output or output by another tool used for running a modules in test
- might be from one or more modules
- the tested code
- code itself with e.g., Pygments or links to Doxygen documentation
- it might be unclear what code to actually include (you can see names of modules, function, you know in which directory test suite was)
- the testing code to see what exactly was tested and failed
- documentation of testing method and
TestCaseclass (extracted docstrings) - related commit/revision number or ticket number
- in theory, each commit or closed ticket should have a test which proves that it works
- this can be part of test method (
test_*) docstring and can be extracted by testing framework
- pictures generated from maps for tests which were not successful (might be applied also to other types but this all is really a bonus)
Generally, the additional data can be linked or included directly (e.g. with some folding in HTML). This needs to be investigated.
Each test (or whatever is generating output) will generate an output file which will be possible to include directly in the final HTML report (by link or by including it into some bigger file). Test runner which is not influenced by fatal errors and segmentation faults has to take care of the (HTML) file generation. The summary pages will be probably done by some reporter or finalizer script. The output of one standalone test script (which can be invoked by itself) will have (nice) usable output (this can or even should be reused in the main report).
Data types to be checked
We must deal especially with GRASS specific files such as raster maps. We consider that comparison of simple things such as strings and individual numbers is already implemented by unittest.
- raster map
- composite? reclassified map?
- color table included
- vector map
- 3D raster map
- color table
- SQL table
- file
Most of the outputs can be checked with different numerical precision.
Resources:
Naming conventions
The unittest.TestLoader.discover function requires that module names are importable (i.e. are valid Python identifiers). Consequently, names of files with tests should contain dots (except for the .py suffix).
Methods with tests must start with test_ to be recognized by the unittest framework (with default setting but there is no reason to not keep this convention).
Name for directory with test is "testsuite". It also fits to how unittest is using this term (set of test cases and other test suites). "test" and "tests" is simpler and you can see it, for example in Python, but might be too general. "unittest" would confuse with the module unittest.
Layout of directories and files
Test scripts are located in a dedicated directory within module or library directories. All reference files or additionally needed data should be located there.
The same directory as tested would work well for one or two Python files but not for number of reference files. In case of C/C++ this would mean mixing Python and C/C++ files in one directory which is strange. One directory in root with separate tree is something which would not work either because tests are not close enough to actual code to be often run and extended when appropriate.
Invoking tests
Test scripts will work when directly executed from command line and when executed from the make system. When tests will executed by make system they might be executed by a dedicated "test_runner" Python script to set up the environment. However, the environment can be set up also inside the test script and not setting the environment would be the default (or other way around since setting up a different environment would be safer).
To actually have separate processes is necessary in any case because only this makes testing framework robust enough to handle (GRASS) fatal error calls and segmentation faults.
Tests should be executable by itself (i.e. they should have main() function) to encourage running them often. This can be used by the framework itself rather then imports because it will simplify parallelization and outputs needs to go to files anyway (because of size) and we will collect everything from the files afterwards (so it does not matter if we will use process calls or imports).
Example run
cd lib/python/temporal
Now there are two options to run the tests. First execution by hand in my current location:
cd testsuite
for test in `ls *.py` ; do
python ${test} >> /tmp/tgis_lib.txt 2>&1
done
The test output will be written to stdout and stderr (piped to a file in this case).
Second option is an execution by the make system (still in lib/python/temporal):
make tests
or
make test
which might be more standard solution.
Testing on MS Windows
On Linux and all other unix-like systems we expect that the test will be done only when you also compile GRASS by yourself. This cannot be expected on MS Windows because of complexity of compilation and lack of MS Windows-based GRASS developers. Moreover, because of experience with different failures on different MS Windows computers (depending not only on system version but also system settings) we need to enable tests for as many users (computers) as possible. Thus, the goal is that we can get to the state where users will be able to test GRASS on MS Windows.
Basically, testing is Python, so it should run. We can use make system but also Python-based test discovery (our or unittest's). Invoking the test script on a MS Windows by hand and by make system may work too. Test will be executed in the source tree in the same way as on Linux. The problem might be a different layout of distribution directory and source code. Also some of the test will rely on special testing programs/modules which on Linux could be compiled on the fly while on MS Windows this could be a huge issue (see more below).
Libraries are tested through ctypes, modules as programs, and the rest is mostly Python, so this should work in any case. However, there are several library tests that are executable programs (usually GRASS modules), for example in gmath, gpde, raster3d. These modules will be executed by testing framework inside testing functions (test_*). These modules are not compiled by default and are not part of the distribution. They need to be compiled in order to run the test. We can compile additional modules and put them to one separate directory in distribution, or we can have debug distribution with testing framework and these modules, or we can create a similar system as we have for addons (on MS Windows) to distribute these binaries. The modules could be compiled a prepared on server for download and they would be downloaded by testing framework or upon user request. The more complex think could be standard modules with some special option (e.g., --test not managed by GRASS parser) which would be available only with some #define TEST and they would not be compiled like this by default.
Locations, mapsets and data
The test scripts should not depend on specific mapsets for their run. In case of make system run, every test script will be executed in its own temporary mapset. Probably location will be copied for each test (testsuite) to keep the location clean and allow multiprocessing. In case of running by hand directly without make, tests will be executed in the current location and mapset which will allow users to test with their own data and projections.
Tests (suites, cases, or scripts/modules) itself can define in which location or locations they should be executed as a global variable (both for unit and doctests, doctests in they their unittest wrapper). The global variable will be ignored in case the test script is executed by hand. When executed by make system, the test can be executed in all locations specified by the global variable, or one location specified by make system (or generally forced from the top). In other words, the global variable specifies what the test want to do, not what it is capable to do because we want it to run in any location.
We should have dedicated test locations with different projections and identical map names. I wouldn't use the GRASS sample locations (NC, Spearfish) as test locations directly. We should have dedicated test locations with selected data. They can overlap with (let's say) NC but may contain less imagery but on the other hand some additional strange data. The complication are doctests which are documentation, so as a consequence they should use the intersection of NC sample and testing location. The only difference between the locations would be the projection, so it really makes difference only for projected, latlon and perhaps XY.
All data should be in PERMANENT mapset. The reason is that on the fly generated temporary mapsets will have only access to the PERMANENT mapset by default. Access to other mapsets would have to be explicitly set. This might be the case when user wants to use his or her own mapset. On the other hand, it might be advantageous to have maps in different mapsets and just allow the access to all these mapsets. User would have to do the same and would have to keep the same mapset structure (which might not be so advantageous) which is just slightly more complex then keep the same map names (which user must do in any case).
If multiple locations are allowed and we expect some maps being in the location such as elevation raster, it is not clear how to actually test the result such as aspect computed from elevation since the result (such as MD5 sum) will be different for each location/projection. This would mean that the checking/assert functions or tests themselves would have to handle different locations and moreover, this type of tests would always fail in the user provided location.
It is expected that any needed (geo-)data is located in the PERMANENT mapset when a specific location is requested. This applies for prepared locations. For running in the user location, it is not a requirement.
The created data will be deleted at the end of the test. The newly created mapset will be deleted (if it was created). If we would copy the whole location (advantageous e.g. for temporal things), the whole location will be deleted. The tests will be probably not required to delete all the created maps but they might be required to delete other files (or e.g., tables in database) if they created some.
User should be able to disable the removal of created data to be able to inspect them. This would be particularly advantageous for running tests by hand in some user specified location.
In case the mapset information is needed, then g.mapset -p (prints the current mapset) must be parsed within the test. An special case, a test of g.mapset -p itself will create a new mapset and then switch to the new one and test there.
Testing framework can have a function to check/test the current location (currently accessible mapsets) whether it contains all the required maps (according to their name).
All reference files (and perhaps also additional data) will be located in the testsuite directory. There can be also one global directory with additional data (e.g. data to import) which will be shared between test suites and exposed by the testing framework.
The reference checking in case of different locations (projections) can only be solved in the test itself. The test author has to implement a conditioned reference check. Alternatively, a function (e.g., def pick_the_right_reference(general_reference_name, location_name)) could be implemented to help with getting the right reference file (or perhaps value) because some naming conventions for reference files will be introduced anyway.
Testing framework design should allow us to make different decisions about how to solve data and locations questions.
Testing data will be available on server for download. The testing framework can download them if test is requested by user. The data can be saved in the user home directory and used next time. This may simplify things for users and also it will be clear for testing framework where to find testing data.
GSoC weekly reports
Week 01
- What did you get done this week?
I discussed the design and implementation with mentor during a week. The result of discussions is on project wiki page (this page, link to version). I will add more in the next days.
The code will be probably placed in GRASS sandbox repository (HTML browser), later it will be hopefully moved to GRASS trunk (HTML browser). However, the discussion about where to put GSoC source code is still open (gsoc preferred source location, at nabble).
- What do you plan on doing next week?
I plan to implement some basic prototype of (part of) testing framework to see how the suggested design would look like in practice and if it needs further refinement. So far it is how I have it in my schedule.
- Are you blocked on anything?
It is not clear to me how certain things in testing framework will work on MS Windows. I will discuss this later on the wiki page and grass-dev.
Attachments (6)
-
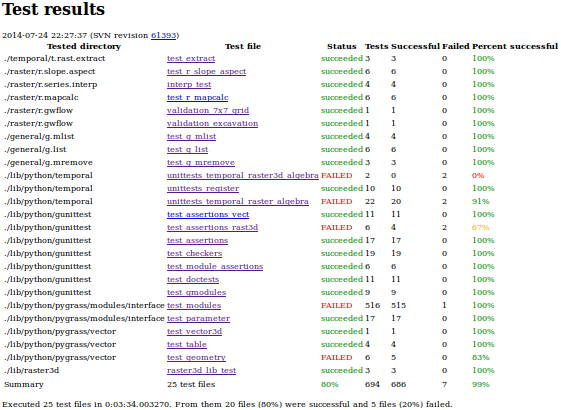
test_files_index.png
(43.5 KB
) - added by 10 years ago.
test files index page in report (week 10)
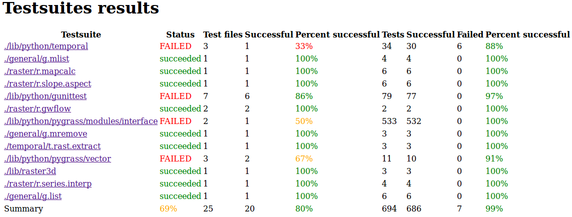
-
testsuites_index.png
(79.8 KB
) - added by 10 years ago.
testsuites index page in report (week 10)
-
testsuite_gmlist.png
(35.3 KB
) - added by 10 years ago.
g.mlist testsuite page in report (week 10)
-
testsuite_gunittest.png
(55.7 KB
) - added by 10 years ago.
gunittest testsuite page in report (week 10)
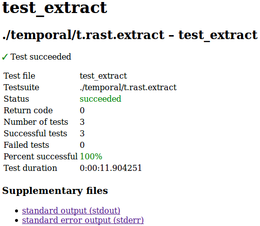
-
test_file_trastextract.png
(36.4 KB
) - added by 10 years ago.
one t.rast.extract test file report page (week 10)
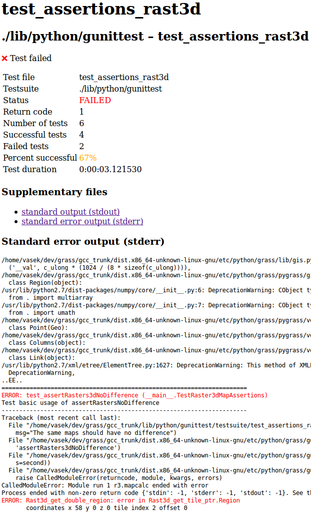
-
test_file_r3assert.png
(157.7 KB
) - added by 10 years ago.
gunittest 3D raster asseritations test file report page (week 10)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip